Compliance and confidentiality challenges
Compliance with laws regarding confidentiality and personal information is one of the hardest challenges we face in the 2020s. Whether you need to restrict access to sensitive data or build a non-production environment that closely mirrors production, manual redaction is not a feasible solution—you simply cannot pay an army of reviewers to read and redact every document one by one.
By redaction, we mean here hiding -and ideally really removing- part of the information in the document content.
Let’s imagine we have a FlowerDocs production environment with a lot of documents randomly confidential or public (note that it is just an example and documents could be on any ECM environment as long as we have a connector for it in Fast2). We want to take those documents, redact the personal and confidential information, then push these documents into a similar non-prod environment.
That way, you end up with a clone-like environment, inducing the same constraints you will face during the production phase, minus the confidential aspect.
Fast2 handles bulk actions on these documents, and will provide all the tools you need for running such campaigns on a large load of artifacts documents. We’ll have extractors, injectors, queue-management, campaign scheduling, reports, etc.. Such a workflow in Fast2 would look a lot like this:
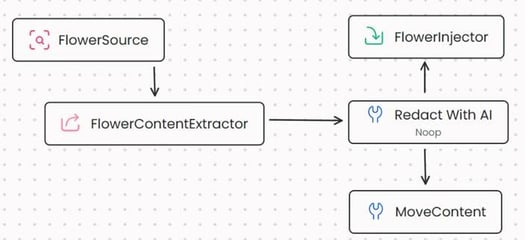
- We start by extracting the list of documents using the FlowerSource.
- Next, we extract the metadata and content of these documents using the FlowerContentExtractor task.
- At this stage, we proceed to redact sensitive information in the documents. (More details on this will be provided later.)
- Finally, we either move the documents to a storage area with a MoveContent task, or we inject them into another FlowerDocs environment via the FlowerInjector task.
Note that we totally could add an AlterDocumentProperties task to change or encrypt the document metadata. Since this metadata is a structured Fast2 object, it is quite handy to manipulate and won’t be discussed in the current post.
About the content however, Fast2 currently doesn’t offer a satisfying task for on-the-fly redaction —it could replace all content with a generic fake content, but this wouldn’t mimic a real content repository.
On the schema above, I put a Noop (no operation) task for clarity purposes, but for now, it doesn’t do anything at all. This is why I decided to build a custom task on Fast2 which would be able to automatically redact documents on the fly.
The idea is to consume two non-Fast2 components:
- the ARender Rendition services on one side, to help us manipulate the content, extract it, and redact the document
- an AI LLM Engine on the other side, to detect the sensitive data we want to redact.
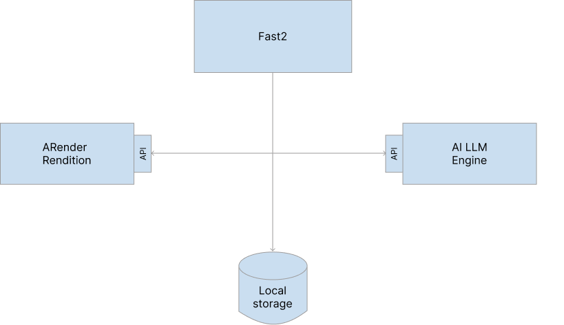
Technical Design, Fast2 tasks is just rocket science but simpler
 For those among us who played Kerbal Space Program (I can’t recommend this game enough), one of the most important lessons about rocket science is that you always conceive stages from the last stage to the first stage, because the design of each stage will completely depend on the design of the next stage.
For those among us who played Kerbal Space Program (I can’t recommend this game enough), one of the most important lessons about rocket science is that you always conceive stages from the last stage to the first stage, because the design of each stage will completely depend on the design of the next stage.
You must think about the tiny capsule for reentry first, then you think about how you will bring it back to Earth (or rather Kerbin), then you think about how you will execute your real mission on the moon (or rather the Mun), then you think about how you will bring this rocket to the moon, then you think about how you will circularize your orbit around the Earth, then you think about how you will bring this big rocket out of the atmosphere. Sometimes, you’ll want to make an Apollo mission (see Apollo program for details) where a module goes to the surface while another stays in orbit, and you must think about two separate ways to follow.
Conceiving a task for Fast2 is about the same logic. You must think about the last step first, then rewind back to the initial situation you have when the task will start.
Here, I want to create a redacted document to replace the original one with a version where no confidential data can be read. I know for sure that ARender Rendition services can do it but they need both the document and some redaction annotations. The document is not an issue, since I have it, but I must remember that I need to send it to the ARender Rendition services.
So I need redaction annotations, and I know that ARender Rendition services can generate such annotations using the document and a regular expression to define the text which must be redacted. So I need a regular expression to define the text to redact, and I know that LLMs are quite good for both semantic analysis and regular expression generation. So I need to be able to send the text of the document in a prompt for an LLM. So I need to extract the text of the document as plain text, which I know ARender can do if I send it the document.
Now, if I rewind my thoughts, here is the plan for this custom task:
- Send the document to the ARender Rendition services
- Extract the text of the document as plain text
- Send the text of the document to an LLM engine
- Ask the LLM engine to produce a regular expression for the confidential information in this text
- Ask ARender Rendition services to generate redact annotations for this confidential information
- Ask ARender Rendition services to produce a redacted version of the document
- Replace the content on the punnet with the newly produced redacted document.
As you can see, since ARender Rendition services already possess most of the intelligence we need, the Fast2 task will be quite simple, and behave more like an orchestrator between ARender and the LLM Engine.
Consuming the ARender Rendition services
Push the document to ARender
ARender Rendition exposes a REST API which is quite easy to consume with a java method. You can check it on your own ARender Rendition instance, which offers a swagger interface to play with. The endpoint we want to consume here is /documents with a PUSH request, which will send a document to ARender and have it stored for later usage.
%201-min.png?width=468&height=392&name=carbon%20(16)%201-min.png)
Just in case, I prepared this code to be able to handle document upload by reference instead of pushing the document as a body in the request. This can be more efficient for big documents, but you must ensure that the reference points to a location available for the Rendition server (which was not my case, so I won’t use it, later in this blog post).
Now I can embed this call into a more business-oriented method which pushes a document to the ARender Rendition services and returns the corresponding document ID for later usage.
Since I’m a very lazy person (and I want to reach my goal before investing too much time in creating a perfect code which I cannot be sure I’ll use in the future), I chose to generate a random UUID and use it as a document ID in ARender instead of interpreting the response from the Rendition services to extract the document ID generated by default by ARender after receiving a new document.
%201-min.png?width=632&height=483&name=carbon%20(17)%201-min.png)
Extract the text from the document
Since we already sent the document to the ARender Rendition services, extracting the text only requires consuming the/documents/{documentId}/pages/{pageNumber}/text/position. Beware that ARender works by page, so in the future we might want to change this code to add a pagination system and be able to loop on pages and analyze them one at a time. In the end, all the annotations will be added to the document, whether they are on the same page or not. Then, if we can do it for one page, we can do it for one thousand pages.
To easily interpret the response from the ARender Rendition services, I use a JSON Object which is built via the ObjectMapper class. This requires us to have java objects with the exact same structure and names as the JSON Objects we want to use. So I have a complete hierarchy of the TextPositionResponse class, as follow:
%202-min.png?width=569&height=308&name=carbon%20(18)%202-min.png)
Then PositionText and ImageHyperlinkPosition are also defined as java classes:
%202-min.png?width=488&height=438&name=carbon%20(21)%202-min.png)
%201-min%20(2).png?width=497&height=334&name=carbon%20(23)%201-min%20(2).png)
And so on until the whole tree is completely covered by java classes (but for primitives, of course). To rebuild this hierarchy, you can refer to the swagger page on the ARender Rendition, which gives the whole structure of responses.
Now that we have a java classes structure which fits the JSON response structure, we can use the ObjectMapper and make a tool method for the text extraction.
%201-min.png?width=524&height=438&name=carbon%20(24)%201-min.png)
We can add a method to embed this call to the Rendition services, and transform the list of TextPositions unto a single text block, as follow:
%201-min.png?width=575&height=209&name=carbon%20(25)%201-min.png)
Now that we have the text, it is time to consume the LLM engine.
Extract the text from the document
For my proof of concept, I used Mistral as the LLM engine. They offer experimental access to its API, which is limited to a few requests but is enough to validate the concept. Since more and more companies add AI services to their own environment, it would be needed to adapt this part so it can consume the precise LLM engine in your own company.
Before typing any code, I hardly suggest testing the prompt on a chat, so you can validate that the answer as an interpretable structure. AI LLM engines tend to try and speak like a human being and will mimic this annoying tendency that humans have to introduce their own answer with a lot of insignificant words. For example, if I ask “give me the color of the sky”, I will probably have an answer like “the sky on Earth can have a variety of colors depending on the time of the day and the incidence of the rays of light from the sun when they enter the atmosphere, but it is generally accepted that the main color of the sky, according to the human perception of it, is blue”.
So we will need to sever the LLM engine intentions to pass for a human being, in order to have a clear and simple answer, which will be easier to interpret by a computer.
Here could be a satisfying prompt “give me the color of the sky, just answer with the name of this color without any explanation nor any context, just give me the name of this color”.
Note the irony of the situation when we have to build more complex prompts to make a machine answer in a way which can be understood by other machines because we created complex machines which try to pass for human beings.
For clarity purposes, I have separated the code in two different methods, one for building the prompt and sending it to the LLM engine, and the other one for interpreting its answer.
%201-min.png?width=693&height=907&name=carbon%20(26)%201-min.png)
%201-min.png?width=570&height=471&name=carbon%20(27)%201-min.png) Now that we have a regular expression to find the confidential and personal information on one page, we can assume that we will be able to do it on several pages with a simple loop.
Now that we have a regular expression to find the confidential and personal information on one page, we can assume that we will be able to do it on several pages with a simple loop.
So we just need to create the redact annotations and to build a new redacted version of our document. For this, all we need is the ARender Rendition services.
Extract the text from the documentBuilding the redacted document
We have three calls to make to the ARender Rendition services. The first one will gather the redact annotations, especially their position on the page, and the other two ones will generate and download a pdf file where the redacted text is completely removed and black boxes are added where this text was before.
For generating the redaction generation, we will use the /documents/<documentId>/pages/0/text?searchText endpoint, and since the document is already uploaded to the Rendition server, this endpoint is already available. I will use, one more time, java classes hierarchy to map the JSON Objects hierarchy. Note that again, there would be a page management to handle if we were to paginate on the document.
For creating the redacted pdf version of the document, we will use the concept of transformations in ARender, by consuming the transformation endpoint /transformations. This endpoint allows us to create a transformation order which we will be assigned a transformation Id we can use to download the result later on.
%201-min.png?width=553&height=442&name=carbon%20(29)%201-min.png)
%201-min.png?width=596&height=1127&name=carbon%20(30)%201-min.png)
Note that again, I’ve been pretty lazy and manipulated the requests and responses as String instead of using proper JSON objects. I hardly discourage any one to use this code as is in a production environment, it would be a mess to maintain.
We now have enough to run this AI-assisted redaction, and Fast2 will need information to treat these methods as an executable task.
Finalizing the Fast2 task
To be considered a Fast2 task, our class must implement the runTask method. It must also explain how its parameters will be displayed in the Fast2 UI.
So here are the little modifications we must make:
%201.png?width=606&height=958&name=carbon%20(31)%201.png) And now this custom task can be run into Fast2, which means I can, with a single click, browse my entire pre-production repository and clean up confidential and personal information. Note that performances can vary since there is a lot to do for each page of a document, so you might want to start with a small amount of documents just to check that it goes smoothly. Remember that Fast2 allows to manage queues and threads, which will make it run faster but will increase the solicitation of the Rendition server and the AI LLM engine.
And now this custom task can be run into Fast2, which means I can, with a single click, browse my entire pre-production repository and clean up confidential and personal information. Note that performances can vary since there is a lot to do for each page of a document, so you might want to start with a small amount of documents just to check that it goes smoothly. Remember that Fast2 allows to manage queues and threads, which will make it run faster but will increase the solicitation of the Rendition server and the AI LLM engine.
As a preview of the result, here is a before and after comparison for an assurance document (names and IDs are fake ones). It’s in French, but you can see that names, IDs, telephone numbers, are now masked under a black box. Note that ARender also removes the text under these black boxes, ensuring that even deep PDF analysis wouldn’t help finding the removed data.

Improvements to make
I tested this code and it runs as is, but in order to make it production-valid, a few improvements need to be made. Here is a non exhaustive list:
- enhance the quality of the code to reach production quality expectations (this is just a PoC, I rushed to the result to maximize the return on investment)
- manage upload by reference toward the ARender Rendition server
- paginate on the document to extract the text and build the redact annotations for each page
- add an OCR step before, to be able to redact image documents
Moreover, it would be relevant to separate the AI consumption from the ARender Rendition services consumption. Since there is a large variety of LLM engines, you might want to use your own, and to code your own custom task for this purpose, but all the ARender Rendition part could be added as a standard and supported Fast2 task - or maybe two, since there is the text extraction before the AI Engine consumption, and the content redaction after the AI Engine consumption.
Then we could create:
A text extraction task, which would extract the text of the content and store it into a metadata field or a new plain text content on the same document
A regex-redaction task, which would expect a regular expression, for instance in a metadata field, and ask ARender to create the redaction annotations and generate a redacted PDF version of the content
If you feel like these are tasks you would appreciate seeing in a future version of Fast2, do not hesitate to reach our portal and submit a suggestion about them.